


I recently had the opportunity to review the IMDA Starter Kit for Testing LLM-Based Applications in Security and Reliability. As someone who has spent more than 14 years in Quality Assurance, I have been curious to see how established evaluation principles are being adapted to address the unique challenges presented by Large Language Models (LLMs).
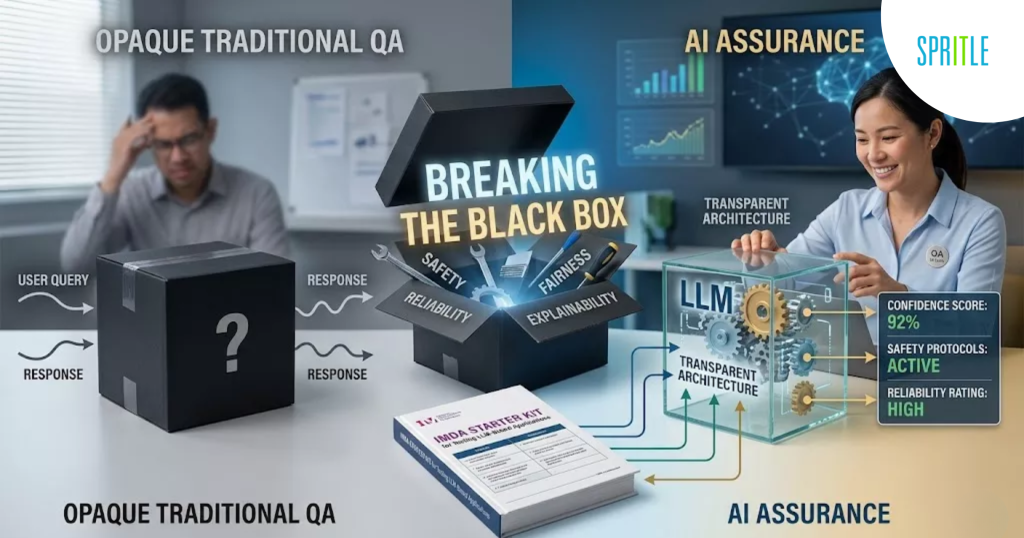
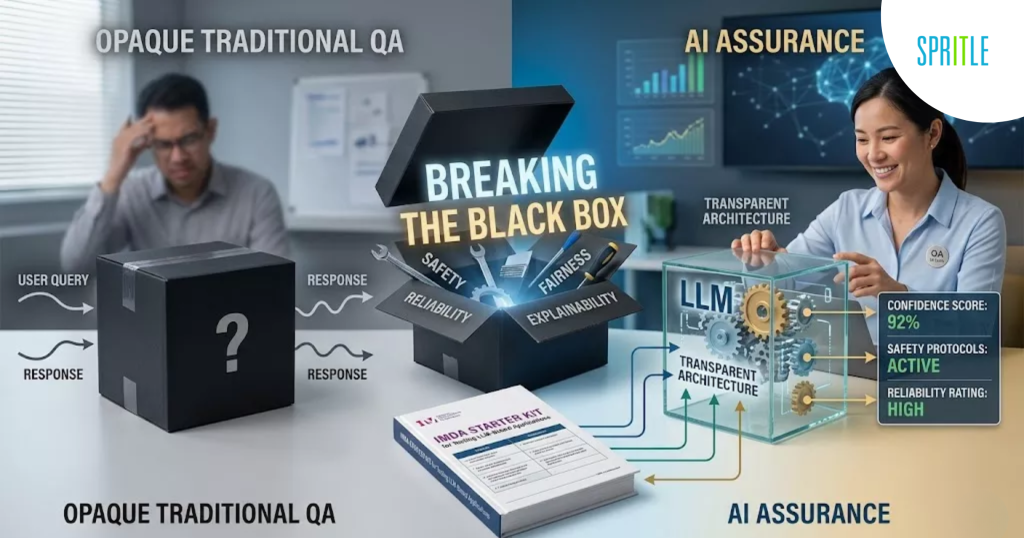
What I expected was a technical guide focusing on AI models and algorithms. What I got instead was a working framework that felt incredibly familiar from a QA perspective. Although the technology may be advancing rapidly, the main objective remains the same: to build confidence that the system behaves safely, reliably, and as intended.
One statement from the document captured this idea well:
“Testing and validation play an important role in a reliable AI ecosystem.”
That message is woven throughout the guide and, in many ways, reflects how the role of quality professionals is evolving today.
Quality Risks Have Changed, The Need for Testing Has Not
One of the first things that stood out was how the document categorized the most common risks associated with LLM-based applications:
· Misperceptions and inaccuracies
· Bias in Decision Making
· Unwanted Content
· Data leakage
· Vulnerability to Adversarial Prompt
At first glance, these may seem like entirely new challenges. However, while reading the explanations and examples, I found myself drawing parallels with the risks that QA teams have been able to manage.
We have always worked to prevent inappropriate system behavior. Today, AI introduces the possibility of negative ideas and creative answers.
We have always considered security and abuse scenarios. Now, rapid injection and counterattacks become part of the threat landscape.
We have always cared about compliance and privacy. Data leakage through AI-generated responses is just a modern extension of that concern.
The terminology may change, but the discipline of identifying, evaluating, and mitigating risk remains at the heart of quality assurance.
A Good Testing Strategy Begins Long Before Testing
Another aspect I liked was the emphasis on preparation before the start of the exam.
The guide spends a lot of time discussing how organizations should identify relevant risks, define assessment objectives, select representative data sets, and establish reasonable parameters before conducting an assessment.
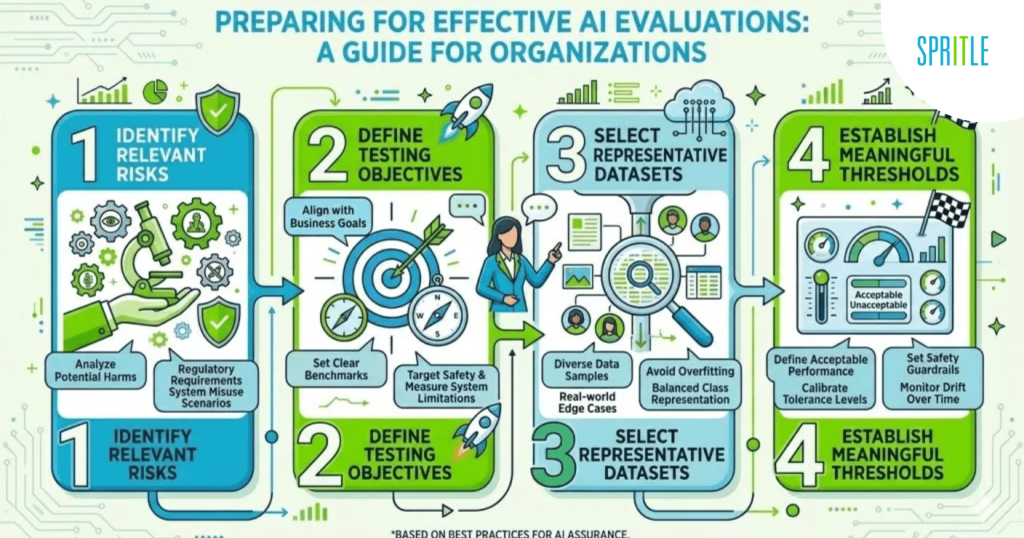
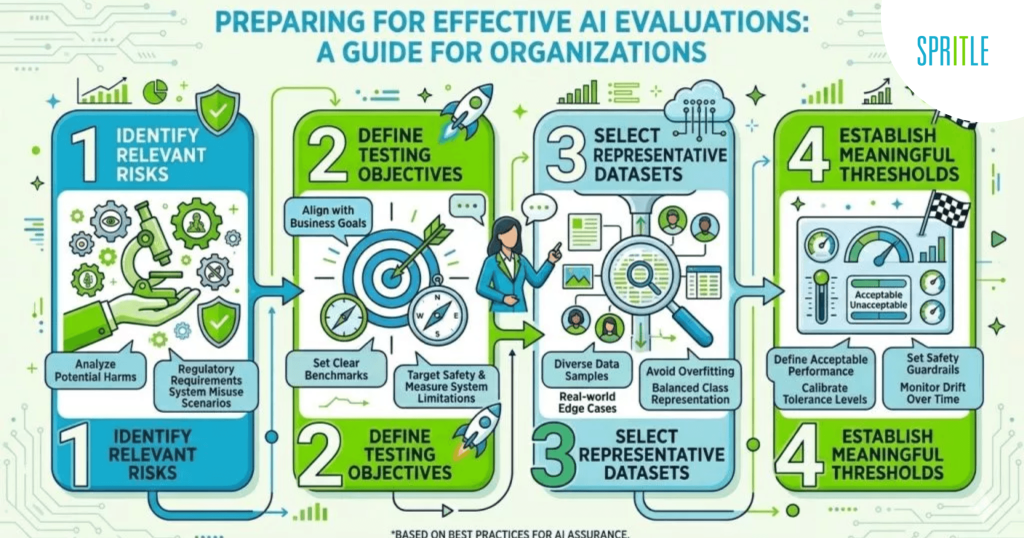
As QA professionals, we know that test success is often determined long before execution begins. Poorly defined objectives, weak test data, or unclear acceptance criteria can undermine even the strongest test cycles.
I especially liked the features revealed in the “good” test dataset. The document emphasizes that data sets should represent the purpose of the application, include real user interactions, and include enough breadth and depth to reveal meaningful stories.
This reflects the same principles we use when designing effective tests for traditional applications.
Another important takeaway was the recommendation to define boundaries before testing begins. This document highlights the importance of avoiding “moving the goalposts” after results are known—a principle that applies strongly to anyone who has worked in quality management.
When Accuracy Alone Doesn’t Tell the Whole Story
The sections discussing metrics and testers were particularly interesting because they challenged the common assumption that accuracy alone defines quality.
The guide explains that metrics should not only be aligned with technical goals but also with business and policy goals. Depending on the use case, organizations may prioritize accuracy, fairness, security, accuracy, recall, or other measures.
This is an important reminder that quality has context.
I also enjoyed the balanced discussion by the testers. This document compares the law-based approach to the LLM-as-a-Judge approach and clearly acknowledges the strengths and limitations of each.
One of the comments I strongly agreed with was the recommendation that automated testing should complement—not replace—human judgment, especially in high-value areas.
As testing professionals, we have always relied on tools to improve efficiency, but the ultimate accountability lies with people. The same principle applies here.
Exploring the Unknown: Why Red Teaming Matters
Of all the sections, the discussion on combining red teams is probably the most thought provoking.
The document makes a clear distinction between measurement and redistribution. Measurement helps confirm known situations, while red collaboration helps reveal blind spots, critical situations, and unexpected behavior.
As I read this section, I couldn’t help but think about the test.
Regular test cases confirm the expected results. Screening tests help uncover problems we didn’t think to write about.
The red team seems to play a similar role in AI systems.
The guide discusses counterintelligence, multi-variable interactions, social engineering techniques, and other methods that can expose weaknesses in AI behavior. It also emphasizes the importance of involving various stakeholders and domain experts to increase the chances of uncovering risks that may remain hidden.
The practical examples included in the document help to reinforce why systematic red team meetings are an important complement to traditional assessment methods.


From Preventing Disability to Ensuring Trust
Perhaps my biggest takeaway from this article is that AI testing is not just another specialized test.
Many of the tasks described—risk prioritization, limit setting, management decisions, human supervision, and interpretation of results—extend beyond engineering teams.
They require collaboration between business stakeholders, product owners, compliance teams, security professionals, and quality professionals.
This is where I see an exciting opportunity for experienced QA staff.
For years, our focus has been on preventing errors and verifying requirements. Increasingly, we are also asked to help organizations understand risk, establish trust, and determine whether systems can be trusted.
That change feels less like a change in tools and more like an evolution of the work itself.
Final Thoughts: Beyond Testing, Toward Validation of AI
One of the strong messages I took away from IMDA’s Starter Kit is that AI assurance is quickly becoming a business capability, not just an experimental exercise.
As organizations implement LLM-enabled applications, success will no longer be measured solely by feature delivery or model performance. It will largely depend on whether organizations can define, manage, monitor, and trust AI-driven decisions with confidence.
At Spritle, we believe this change requires QA teams to evolve into key partners in AI adoption. The future of quality depends not only on verifying outputs but also on understanding system behavior, identifying risks early, and helping to establish lines of surveillance that allow for responsible innovation.
Organizations like IMDA provide an excellent foundation, but their real value comes from their effectiveness within business environments. That means integrating engineering discipline, domain expertise, management processes, and continuous assurance into an iterative process.
As AI systems become more powerful, the question organizations will be asking is not just “Does it work?“
It will be like this:”Can we trust the scale?“
Helping answer that question is where we see the future of Quality Engineering—and the direction we’re actively investing in at Spritle.



