
Lessons from the IMDA’s First LLM Assessment Kit: An AI Confidence Perspective


Quality Assurance has always been about understanding risks and validating systems before they reach production. After more than eight years in QA and now working in AI security, management, and red collaboration, I often compare common testing practices to the challenges presented by AI systems.
While the risks range from software vulnerabilities to vulnerabilities, rapid injections, and data leaks, the goal remains the same: to build confidence that systems behave safely, reliably, and as intended.
That’s why I found the IMDA Starter Kit for Testing LLM-Based Applications in Security and Reliability particularly valuable. It approaches AI testing not as a one-time task, but as an ongoing process to identify risks, validate controls, and build trust in AI systems.
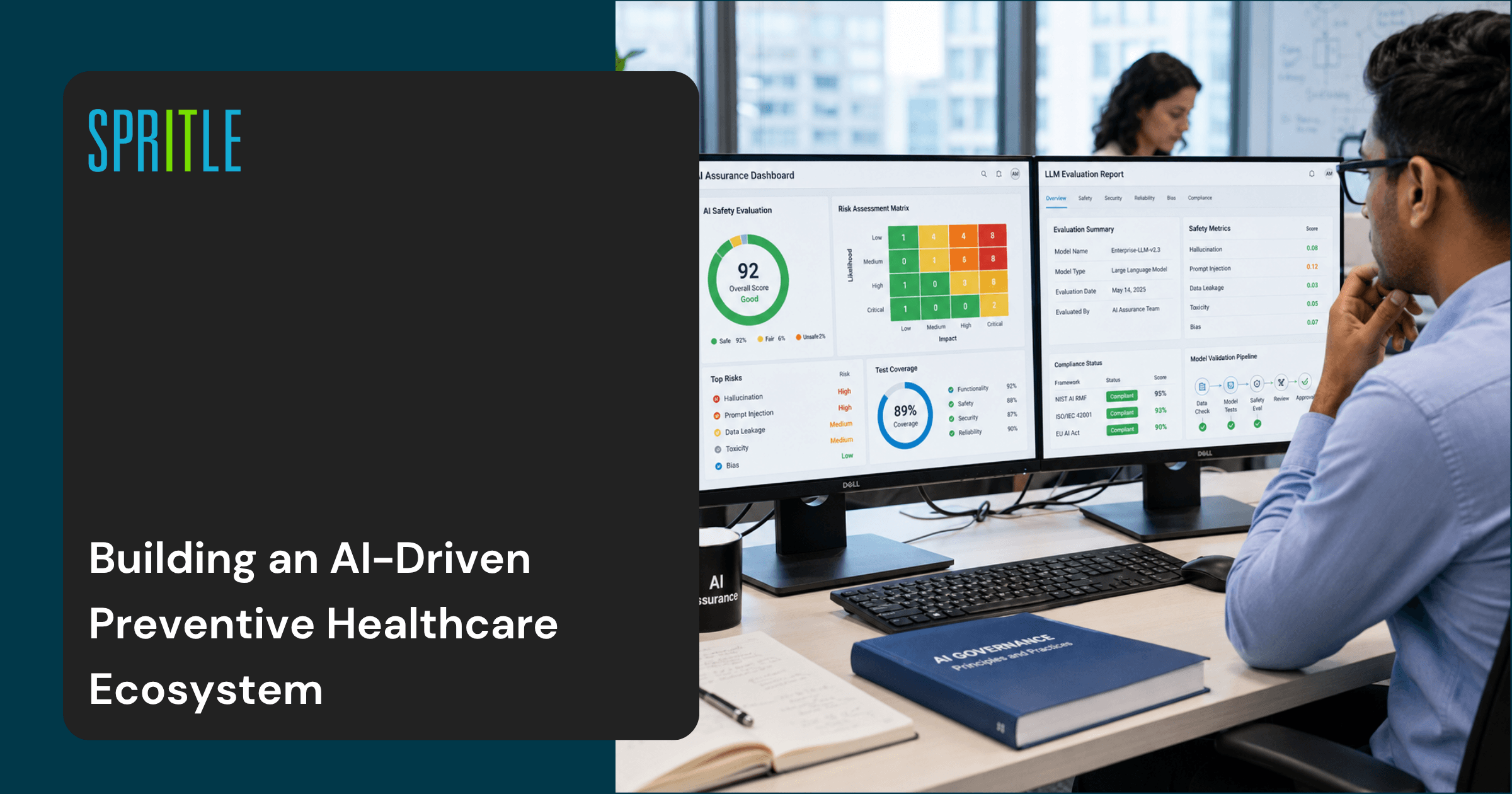
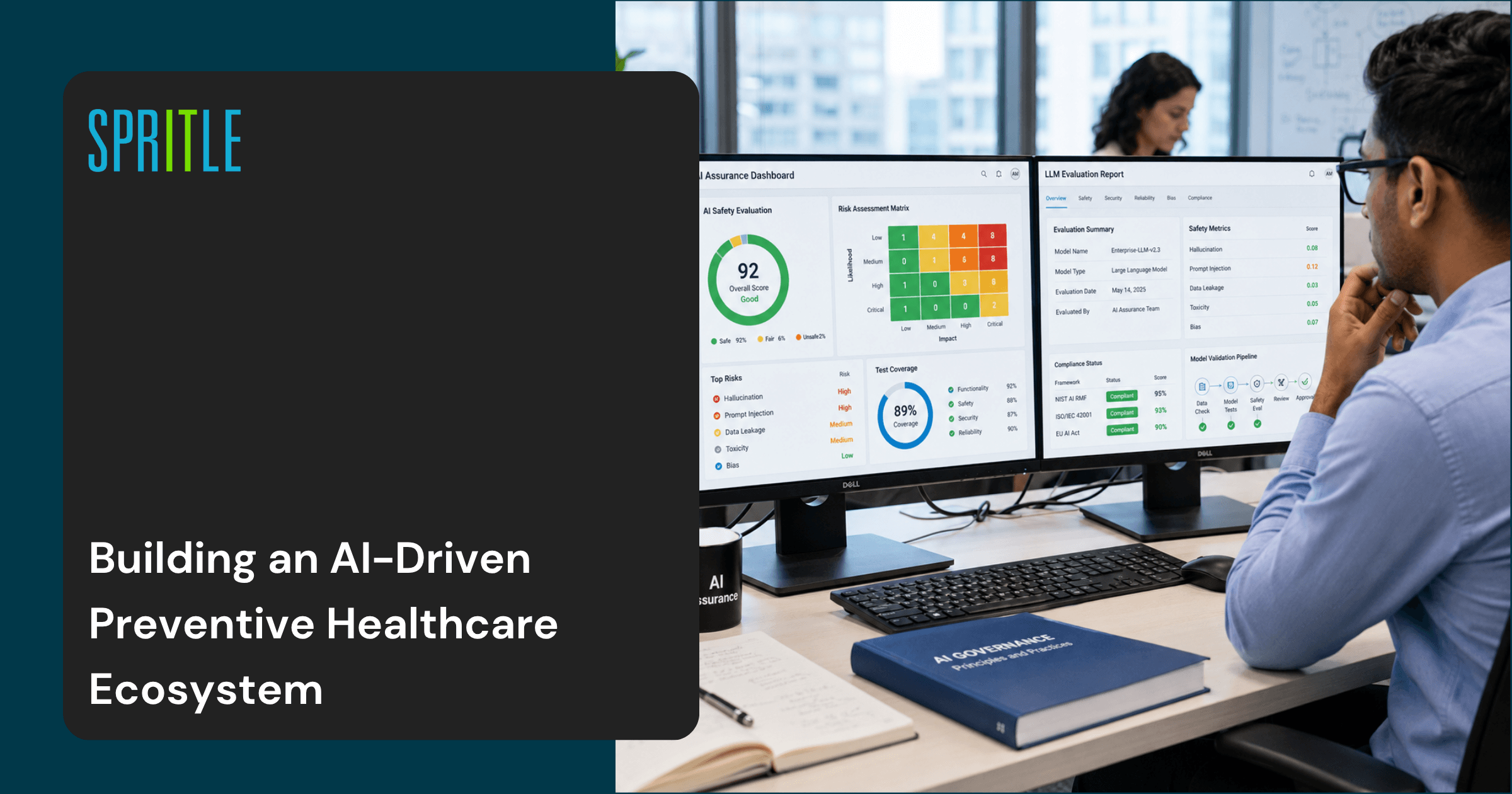
What I Appreciated The Most
One of the strongest features of the Starter Kit is its simplicity.
The framework narrows AI testing into five critical areas:
- Hallucinations and Inaccuracies
- Bias in Decision Making
- Unsolicited Content
- Data Leakage
- Vulnerability to Adversarial Prompts
One of the reasons these categories resonated with me is their relevance to many risk organizations today. Another thing that stood out to me was this strong alignment between these risk areas and the OWASP Top 10 LLM applications.
Risks such as rapid injection, disclosure of sensitive information, and unreliable results are common findings during AI security testing and red team exercises, making the framework applicable to both AI assurance and security testing.
Real-time example: When testing an AI application, especially chatbots connected to internal data sources, the main concern is rarely model accuracy alone. Common results include:
- Risks of rapid injection exceeding safety instructions
- Disclosure of sensitive information through retrieval pipes
- Objective answers presented with great confidence
- Unsafe results produced by the interaction of multiple curves
- Information on system vulnerabilities that can be exploited by attackers
What impressed me is how the framework effectively handles these risks in a systematic and feasible manner. The categories are broad enough to be used across different use cases while remaining applicable to use groups.
Combined with objective test cases, i The Starter Kit provides a solid foundation for organizations looking to build or mature their AI certification programs.


Output Testing vs. Component Testing: A Lesson Every Team Needs to Learn
One of the most important lessons in the Starter Kit is the difference between output testing and component testing.
The guide emphasizes that testing should go beyond model responses to include internal components such as system instructions, filters, retrieval systems (RAG), knowledge bases, and the underlying model.
This is very similar to what we see during red group reunion programs.
A chatbot may appear secure during normal interactions while still containing vulnerabilities within its retrieval layer, rapid orchestration, or monitoring queues. In most experiments, risk is not found because the final response appears to be dangerous, but because internal mechanisms can be altered to ultimately produce unsafe results.
In fact, some of the most important findings come from fast models that reveal hidden instructions, retrieval methods that return unauthorized information, weak filter controls, or insecure orchestration between models and tools. These problems usually remain undetected during standard output validation.
The key takeaway is simple:
1. Test model responses alone rarely provide a complete picture of an application’s security posture.
Some of the more serious consequences come from:
- Quick templates that reveal hidden instructions
- Retrieval methods that return unauthorized information
- Weak content filtering controls
- Secure orchestration logic between models and tools 2. Component-level testing is often where organizations uncover issues that miss traditional output validation. The Starter Kit’s emphasis on these differences is one of its most effective recommendations.


Red Team Without Quick Injection
One of the biggest misconceptions in the industry is that red AI interactions are all about jailbreaking and quick injections.
The Starter Kit takes a much broader view, defining red interactions as a way to uncover blind spots, test multiple interactions, and identify risks that benchmark testing might miss.
This corresponds closely to real-world experience. Most impactful risks do not arise from a single information from an adversary. Instead, they appear through:
- Content accumulation across conversations
- Simulated attack
- Retrieval illusion
- Indirect rapid injection
- Target hijacking using a tool
- Multi-step attack chains
The framework reinforces an important fact: benchmarking helps measure known risks, while red teaming helps uncover unknown risks. Both are necessary for a mature AI authentication system.
Hard benchmarks can provide useful coverage and reproducibility, but they cannot fully capture the unpredictable ways of users, attackers, and complex business environments interacting with AI systems. A human-led red team is always essential in uncovering those hidden failure modes.
What Can Be Added to the Starter Kit
The Starter Kit provides a solid foundation for today’s LLM applications, but the next generation of AI systems will need evolving testing methods around them.
1. Strong Installation of Agentic AI
The industry is rapidly moving from chatbots to autonomous agents that can invoke tools, access external systems, store memory, and take actions on behalf of users.
Agent Systems introducing entirely new risk categories, including:
- Unauthorized instrument making
- Agent-to-agent communication
Conventional knowledge-based testing is often insufficient to evaluate these systems because risk no longer resides only in what the model says—it also resides in what the model can do.
An agent that cannot interact with ticketing systems, databases, cloud services, or financial applications creates an entirely different attack surface. Future evaluation frameworks will require methods that examine decision-making processes, action execution, consent parameters, and multi-agent interactions.
2. Expanded Focus on Sustainable Governance
The document focuses mainly on pre-shipment testing.
In business environments, however, risks often arise after deployment when information, models, data sources, retrieval systems, or business workflows change.
AI validation should be considered as a continuous life cycle rather than a deployment test. In fact, many organizations face more risk from post-deployment changes than from the original model release itself.
Future versions may emphasize:
- Continuous monitoring
- AI asset management
- Model and follow change quickly
- Governance controls
- Periodic re-examination
- Risk trend analysis
This will help organizations maintain certainty as systems evolve over time.
3. Strict Alignment with Emerging Regulations
The Starter Kit indicators have established international frameworks, incl NIST and ISO.
Future versions could go further by mapping test functions directly to emerging governance and control frameworks such as:
- UNESCO Recommendation on the Ethics of AI
- Some emerging national AI laws
Such planning can help organizations link the results of technology audits to broader governance, compliance, and risk management responsibilities.
My Key Takeaway
AI validation isn’t about detecting vulnerability—it’s about building trust.
The framework follows a simple but powerful cycle:
Point → Check → Check → Minimize → Recheck
This shows how mature AI security systems work in practice.
The real value of testing is not just identifying risks, but implementing mitigations, ensuring their effectiveness, and demonstrating measurable risk reduction over time.. As the adoption of AI grows, organizations increasingly need proof that their security, safety, and regulatory controls remain effective as systems evolve.
Ultimately, effective AI validation is not measured by the number of risks detected, but by an organization’s ability to continuously mitigate risk as AI systems evolve.
The IMDA Starter Kit effectively bridges the gap in between theory and practice by providing a systematic approach that startups, businesses, security teams, auditors, and management professionals can put into practice.
As someone who spends each day testing AI systems through red teaming, governance, and security testing, the Starter Kit felt less like a theoretical framework and more like a practical demonstration of what effective AI assurance should look like in the real world.
The challenge is no longer whether AI systems should be tested, but whether our testing, management, and validation processes can evolve quickly enough to keep pace with autonomous and business-critical AI systems. The IMDA Starter Kit provides an essential foundation for that journey.



