
NVIDIA and University of Maryland Researchers Release Audio Flamingo Next (AF-Next): The Most Powerful and Open Source Audio Language Model
: The Most Powerful and Open Source Audio Language Model")
Sound perception has always been a multimodal frontier that lags behind vision. Although pictorial language models have grown rapidly into real-world applications, building open models that robustly account for speech, natural sounds, and music — especially length — remains difficult. NVIDIA and University of Maryland researchers are now bridging that gap.
The research team has released Audio Flamingo Next (AF-Next)the most capable model in the Audio Flamingo series and the fully open Large Audio-Language Model (LALM) trained on internet-scale audio data.
Audio Flamingo Next (AF-Next) enters three special types of use for different cases. Exclusions include AF-Next-Command to answer general questions, AF-Next-Think of advanced multi-step thinking, too AF-Next-Captioner for detailed audio snippets.
What is the Large Audio Language Model (LALM)?
A The Large Audio Language Model (LALM) pairing an audio encoder with a language-only decoder model to enable querying, captioning, transcription, and reasoning directly over audio input. Think of it as the audio equivalent of a visual language model like LLaVA or GPT-4V, but designed to handle speech, natural sounds, and music at the same time – within one integrated model.
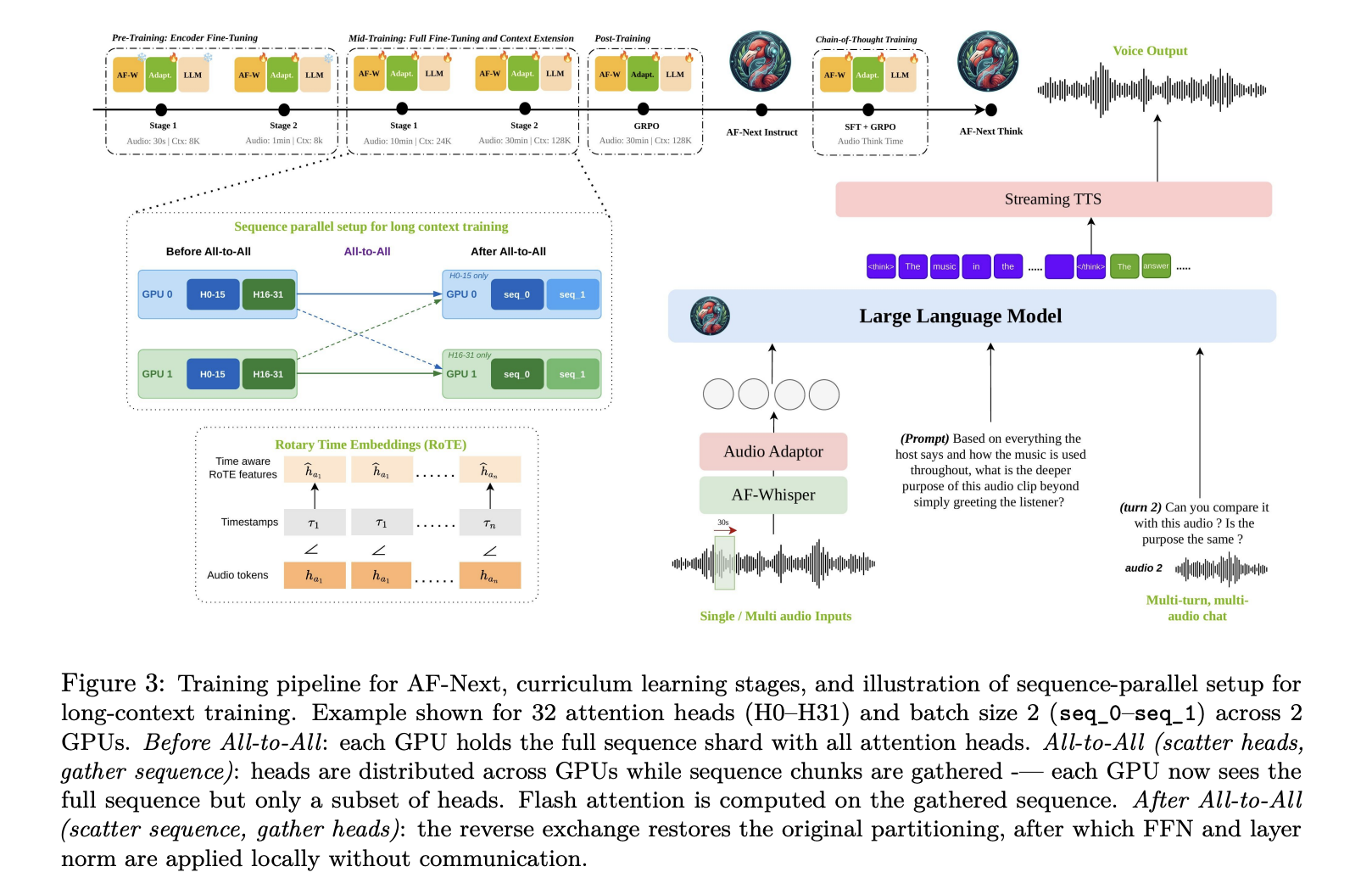
Architecture: The Four Components of the Pipeline
AF-Next is made up of four main parts: First is AF-Whisper audio encodera custom Whisper-based encoder pre-trained on a large and highly diverse corpus, including multilingual speech and multi-talker ASR data. Given an audio input, the model resamples it to 16 kHz mono and transforms the waveform into a 128-log mel-spectrogram using a 25 ms window and 10 ms hop size. The spectrogram is processed in non-overlapping 30-second slices with AF-Whisper, which extracts features at 50 Hz, after which a stride-2 smoothing layer is applied. The hidden dimension is 1280.
The second is audio adaptera 2-layer MLP showing AF-Whisper sound representations in the language model embedding environment. The third is LLM trade volume: Qwen-2.5-7B, decoder-only causal model with 7B parameters, 36 transformer layers, and 16 attention heads, context length extended from 32k tokens to 128k with additional training for long content.
A subtle but important architectural detail Rotary time embedding (ROTE). Standard encoding in transformers identifies a token by its variable sequence position i. RoTE replaces: the standard RoPE rotation angle θ ← −i · 2πROTE uses θ ← −τi · 2πwhere τi is the absolute timestamp of each token. For sound tokens generated in a constant 40 ms stride, the different time positions are combined before being fed into the RoTE module. This results in real-time based positional representations instead of sequential order – a key design choice that enables the model’s temporal reasoning, especially for long-range noise. Finally, a streaming TTS module it enables word-to-word communication.
The Temporal Sound Chain of Thought: A key recipe for reasoning
Chain-of-Thought (CoT) information has improved reasoning across text and visual models, but previous audio CoT work showed only modest benefits because training datasets were limited to short clips with simple questions. AF-Next talks about this The Logical Chain of Temporal Soundwhen the model clearly reinforces each intermediate step of reasoning in the time step in the noise before generating the response, it promotes the collection of reliable evidence and reduces hallucinations with long recordings.
To train this skill, a research team was formed AF-Think-Timea dataset of question–answer–psychological triplets selected from challenging audio sources including trailers, movie recaps, mystery stories, and long multi-group interviews. AF-Think-Time consists of approximately 43K training samples, with an average of 446.3 words per thought stream.
Training at Scale: 1 Million Hours, Four Phases
The final training dataset includes approximately 108 million samples and approximately 1 million hours of audio, taken from both existing publicly released datasets and raw audio collected from the open internet and subsequently artificially labeled. The new data sets introduced include over 200K long videos lasting 5 to 30 minutes for long-form captioning and QA, multi-speech understanding data including speaker identification, interference detection, and target speaker ASR, nearly 1 million samples of multi-audio imaging of multiple simultaneous audio inputs, and tracking of 386K safety samples.
Training follows a a four-phase curriculumeach with different data mixes and context lengths. Pre-training it has two sub-stages: Stage 1 trains only the audio adapter while keeping both AF-Whisper and LLM frozen (30 seconds audio maximum, 8K token core); Stage 2 also fine-tunes the audio encoder while keeping LLM tight (1 minute audio max, 8K token core). Intermediate training and we have two sub-stages: Stage 1 performs a full optimization of the entire model, adding AudioSkills-XL and newly selected data (max audio 10 minutes, 24K token core); Stage 2 introduces longer audio snippets and QA, down-sampling the Stage 1 mix to half its original mix weights while extending the core to 128K tokens and the audio to 30 minutes. The model from intermediate training is directly output as AF-Next-Captioner. After training uses GRPO-based reinforcement learning focused on dynamic conversation, safety, following instructions, and selected skill-specific datasets, producing AF-Next-Command. Finally, CoT training starts from AF-Next-Instruct, applies SFT to AF-Think-Time, then GRPO uses a mixture of post-training data, generating AF-Next-Think.
One notable contribution of the research team is hybrid sequence parallelismwhich makes 128K content training possible in long audio. Without it, the expansion of the audio token exceeds the standard context windows and the quadratic memory cost of attention becomes impossible. The solution combines the attention of Ulysses – which uses clusters that reach all the distribution of the sequence and the size of the head within the nodes where high bandwidth connections are available – with the attention of the Ring, which circulates the blocks of important value to all the nodes with point-to-point transmission. Ulysses handles intra-node communication well; Run scales on all nodes.
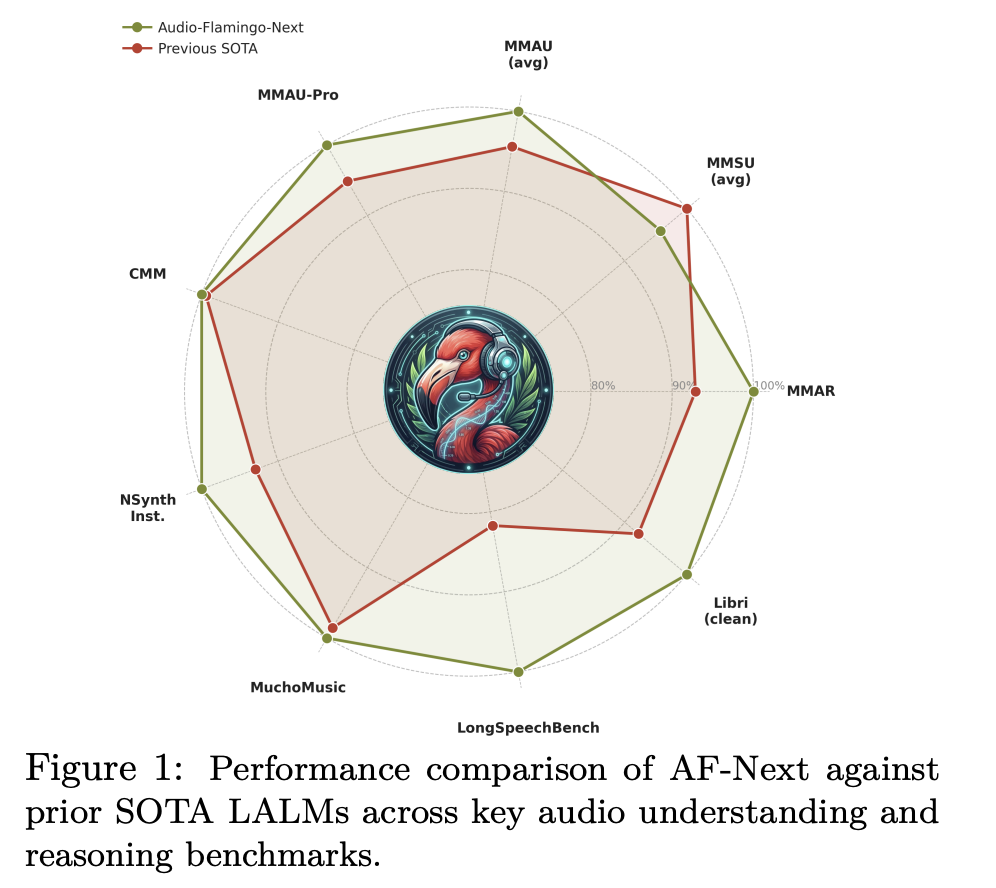
Benchmark Results: Solid Across the Board
In MMAU-v05.15.25, the most widely used noise reasoning benchmark, AF-Next-Instruct achieves an average accuracy of 74.20 vs. Audio Flamingo 3’s 72.42, AF-Next-Think reaches 75.01 and AF-Next. subcategories: sound (79.87), music (75.3), and speech (72.13). In the challenging MMAU-Pro benchmark, AF-Next-Think (58.7) outperforms the closed-source Gemini-2.5-Pro (57.4).
Understanding music sees particularly powerful benefits. In Medley-Solos-DB metal attention, AF-Next reaches 92.13 vs. Audio Flamingo 2’s 85.80. For SongCaps music captions, GPT5 coverage and accuracy scores jump from 6.7 and 6.2 (AF3) to 8.8 and 8.9 respectively.
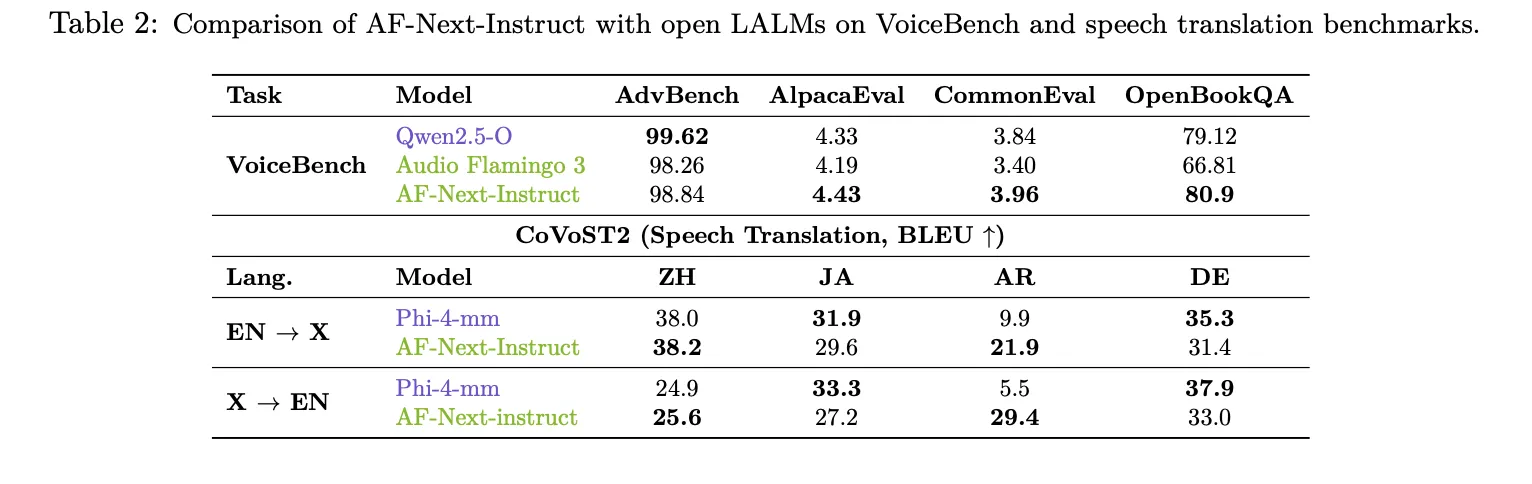
Long range sound understanding is where the AF-Next clearly sets itself apart. In LongAudioBench, the AF-Next-Instruct scores 73.9, outperforming the Audio Flamingo 3 (68.6) and the closed-source Gemini 2.5 Pro (60.4). In the difference involving speech (+Speech), AF-Next reaches 81.2 vs. Gemini 2.5 Pro’s 66.2. In ASR, AF-Next-Instruct sets a new low among LALMs with a Word Error Rate of 1.54 in LibriSpeech test-clean and 2.76 in other tests. In VoiceBench, AF-Next-Instruct scores high in AlpacaEval (4.43), CommonEval (3.96), and OpenBookQA (80.9), beating Audio Flamingo 3 by more than 14 points in OpenBookQA. In CoVoST2 speech translation, AF-Next shows a significant improvement of 12 points over Phi-4-mm in Arabic EN→X translation (21.9 vs. 9.9).
Key Takeaways
Here are 5 key takeaways:
- A Fully Open Audio Language Model at Internet Scale: AF-Next is considered the first LALM to measure audio intelligibility on internet-scale data – approximately 108 million samples and 1 million hours of audio.
- A Series of Transient Sound Reasoning Solves Long Sound Reasoning: Rather than thinking like previous CoT methods, AF-Next implicitly embeds each intermediate thought step in a timestamp in the noise before generating a response. This makes the model even more reliable and descriptive for long recordings of up to 30 minutes – the previous problem is greatly reduced.
- Three Special Varieties for Different Use Cases: Releases include AF-Next-Instruct for answering common questions, AF-Next-Think for advanced multi-step reasoning, and AF-Next-Captioner for detailed audio captions — allowing experts to choose the right model based on their task rather than using a one-size-fits-all test environment.
- Beats Closed Models in Loudness Despite Being Small On LongAudioBench, the AF-Next-Instruct scores 73.9 — outperforming the closed-source Gemini 2.5 Pro (60.4) and Audio Flamingo 3 (68.6). In another challenging speech category, the gap widens, with AF-Next reaching 81.2 vs. Gemini 2.5 Pro’s 66.2.
Check out Paper, Project Page and Model Weights. Also, feel free to follow us Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



