
Liquid AI Releases LFM2.5-8B-A1B: In-Device MoE Model With 8.3B Value and 1.5B Functional Parameters

Liquid AI just shipped LFM2.5-8B-A1B. It’s a Mixture-of-Experts (MoE) device model built for toolkits. The model holds a total of 8.3B parameters but activates only 1.5B per token. That sparsity is what allows it to run on consumer hardware.
The release follows the LFM2-8B-A1B, which the Liquid AI team previously published. LFM2.5 is a new family of hybrid models for device implementation. This version adds a 128K context window, reasoning, and increased training.
What is LFM2.5-8B-A1B
The model uses a small MoE design. It unlocks 1.5B of a total of 8.3B parameters per forward pass. That keeps each token generated cheap to count.
The building has 24 floors. Eighteen are LIV blocks with two gates; six are GQA layers. It includes MoE, GQA, and short gated blocks. The length of the context is 131,072 tokens. The model includes nine languages, including Arabic, Chinese, and Japanese.
The Liquid AI team recommends a temperature of 0.2, a top_k of 80, and a penalty_repetition of 1.05.
Unlike its predecessor, the LFM2.5-8B-A1B is a concept-only model. It presents a clear train of thought before its final answer. The Liquid AI team chose this because MoE models work in computationally constrained settings. The small number of active parameters makes each logic token cost-effective.
What Has Changed Since the LFM2-8B-A1B
Liquid increased the context window from 32,768 tokens to 128,000. Pre-training is rated from 12T to 38T tokens. The vocabulary has doubled from 65,536 tokens to 128,000.
A larger vocabulary encodes non-Latin texts very well. The Liquid AI team reports the strongest compression gains in Hindi, Thai, Vietnamese, Indonesian, and Arabic. The rest of the architecture remains the same as the LFM2-8B-A1B.
How Liquid AI Trained
The Liquid AI team stretched the token in place instead of retraining it from scratch. Continued BPE compilation training since the original compilation on the multilingual corpus. New embedding lines begin as a description of the decomposition of their smaller tokens. A short two-stage practice then restores quality.
The content expansion came in two phases. The 2T token training section reached 32K, focusing on logic, math, and tool use. Raising the base of RoPE θ, and the stage of 400B tokens, reached 128K.
Two classes of reinforcement studies are directed at known failure modes. A preference optimization section reduces ‘doom loops’ in long-term tracking. It also distributes the maximum number of possibilities to the possible paths. A separate award for RL formatting discourages looping restart words like ‘Wait…’. Another RL class uses a reward based on avg@k to cut out missing views. The goal is to avoid questions beyond reliable information.
The Benchmark Case
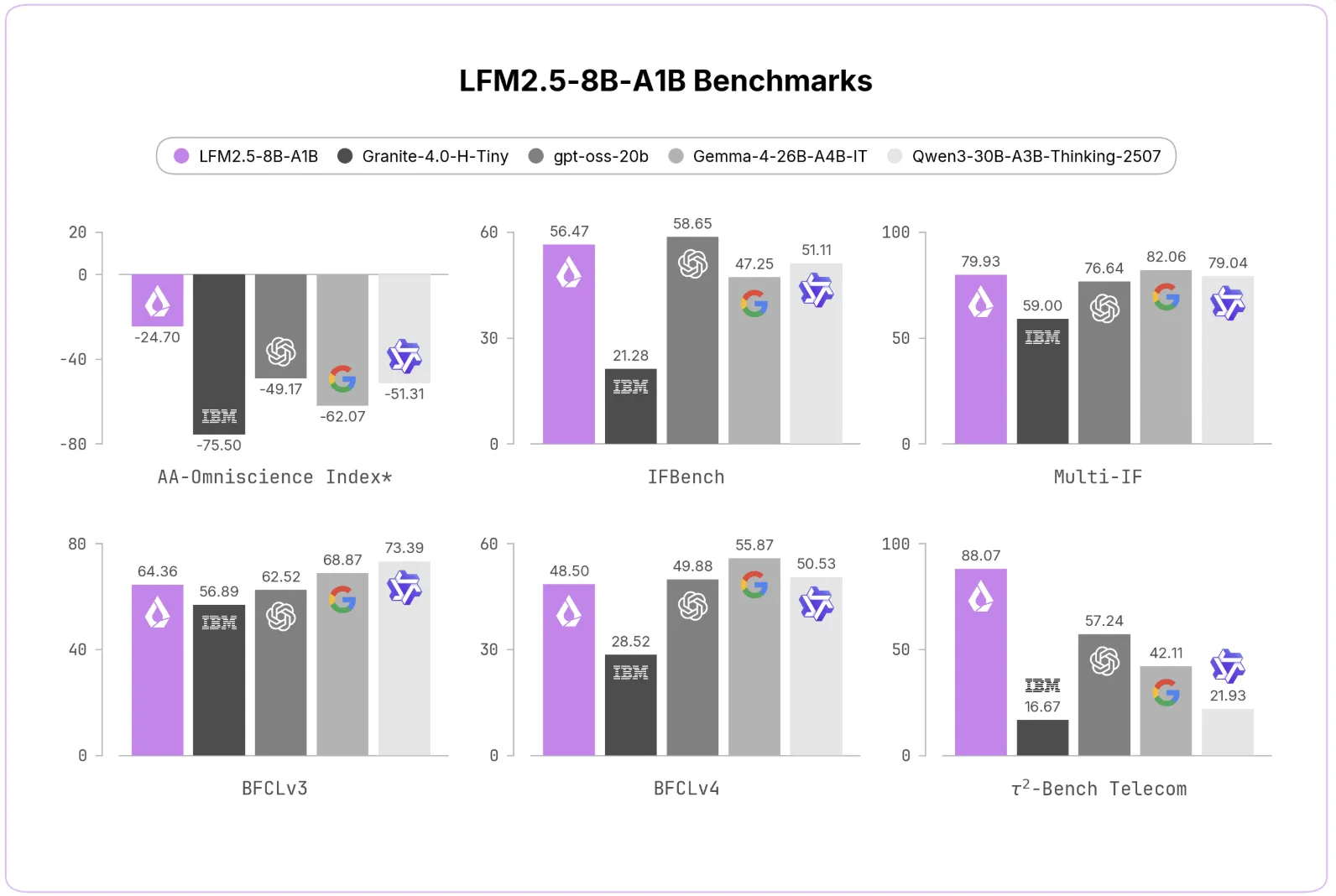
The LFM2.5-8B-A1B improves on its predecessor across the board. The AA-Omniscience Non-Hallucination Rate jumped from 7.46 to 63.47. FEval increased from 79.44 to 91.84. MATH500 increased from 74.80 to 88.76. Tau² Telecom rose from 13.60 to 88.07.
The Liquid AI team compared the model with other dense and MoE methods. In the next command, match Gemma-4-26B-A4B-IT to IFEval. Do so in the active parameter calculation section. In Tau² Telecom, it gets a score of 88.07, ahead of the biggest models.
The avg@k award conveys the lowest rate of hallucinations. Accuracy remains reasonable with model size. In agent benchmarks, it remains competitive with larger models.
| Benchmark | LFM2-8B-A1B | LFM2.5-8B-A1B | Δ |
|---|---|---|---|
| AA-Omniscience Non-Hallucination Rate | 7.46 | 63.47 | +56.01 |
| FEval | 79.44 | 91.84 | +12.40 |
| MATH500 | 74.80 | 88.76 | +13.96 |
| Tau² Telecom | 13.60 | 88.07 | +74,47 |
The model runs with one-day support across the entire inference ecosystem. Frameworks include llama.cpp, MLX, vLLM, and SGlang. ONNX and Liquid’s LEAP edge platform are also supported.
On the CPU, it issues 253 tokens/s on the M5 Max. It reaches 146 tokens/s on the Ryzen AI Max+ 395. It stays under 6 GB of memory all around. On the phone, it handles about 30 tokens/s.
On one NVIDIA H100 SXM5, the throughput hits 18.5K tokens per second. That’s over 1.6B tokens per day at high compatibility.
Using the tool, LFM2.5 writes Pythonic calls automatically. They appear between <|tool_call_start|> again <|tool_call_end|> special tokens. You can output this to JSON in the system notification.
Power and What to Watch
Power:
- Enables only 1.5B parameters, keeping guesswork cheap on edge hardware
- Following the competitive instructions and agency scores for its size class
- 128K content window and nine language input
- Open weight under the LFM1.0 license, with basic and post-training checkpoints
A Must Watch:
- The amount of information is limited from the calculation of the smallest effective parameter
- Not suitable for heavy programming or QA that requires information without retrieval
- Thought output only adds thought tokens to every turn
- Text only; this variant has no vision or audio input
Marktechpost Visual Explainer
Key Takeaways
- Liquid AI’s LFM2.5-8B-A1B holds a total of 8.3B parameters but activates only 1.5B per token.
- It’s just a concept, with a 128K core window and nine language inputs.
- The Non-Hallucination Rate jumped from 7.46 to 63.47 over LFM2-8B-A1B; FEval reached 91.84.
- It determines 253 tok/s on the M5 Max under 6 GB, and ~30 tok/s on the phone.
- Day-one support includes llama.cpp, MLX, vLLM, and SGlang, with open source and post-trained weights.
Check it out Model weights again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



