
Google AI Research Proposes Vantage: An LLM-Based Protocol for Measuring Collaboration, Creativity, and Critical Thinking

Standard tests can tell you whether a student knows calculus or can analyze a passage of text. What they can’t reliably tell you is whether that student can resolve a disagreement with a colleague, generate original ideas under pressure, or seriously dissect a flawed argument. These are so-called long-term skills – collaboration, creativity, and critical thinking – and for decades they have resisted strict, dangerous measurement. A new study from Google Research proposes a technological solution called Vantage: large language models that can simulate real team interactions and get results with the accuracy of human expert partners.

The Key Issue: Natural vs. Psychometric Rigor
To understand why this is technically interesting, it helps to understand the measurement puzzle the research team was trying to crack. Measuring long-term skills successfully requires two conflicting factors. On the other hand, testing needs to be ecologically valid – it must sound like a real-world situation, because that is the very context in which these skills are used. On the other hand, it requires psychometric rigor: standard conditions, reproducibility, and controllable stimuli so that scores can be compared across test takers.
Previous large-scale efforts, such as the PISA 2015 collaborative problem-solving assessment, have attempted to solve this by having subjects collaborate with teammates who model the text through multiple-choice questions. That ensures control but sacrifices authenticity. Person-to-person testing does the opposite. LLMs, the research team argues, are uniquely positioned to satisfy both requirements at once – they can produce natural, open-ended conversational interactions while being systematically guided toward specific assessment goals.
Advanced LLM: The Coordinating Layer Beyond AI Agents
The most technically distinct contribution of this study is the Executive LLM architecture. Rather than spawning multiple independent LLM agents – one for the AI partner – the system uses a single LLM to generate responses for all AI participants in the conversation. This is important for two reasons.
First, it enables communication. The Executive LLM has access to the same teaching rubric that will later be used to assess the candidate. It uses this rubric not just passively, but actively – it directs the discussion to situations that bring evidence of certain skills. For example, if the objective dimension is conflict resolution, an Advanced LLM might instruct one of its AI humans to present the conflict and support it until the human participant demonstrates (or fails to demonstrate) a conflict resolution strategy. This functionality is similar to how a computerized adaptive test (CAT) adjusts item difficulty based on the performance of the examinee in action – except here, the ‘items’ are exchanged in a live interview.
Second, the basis of independent agents (separate LLMs with no interaction) proved to be visually weak. Without guidance, discussions may not produce relevant evidence – if group members naturally agree, there is no conflict to be resolved, and the experiment learns nothing from that little information.
The Gemini 2.5 Pro is used as a sub-model for the Executive LLM for the core collaborative assessment, while the Gemini 3 enables creativity and critical thinking modules.
What Tests Really Show
The research team recruited 188 participants aged 18-25, native English speakers based in the United States, using the Prolific platform. Each participant produced two interviews for a total of 373 transcripts (three were filtered out due to technical issues). All participants worked on collaborative tasks – either the design of a scientific experiment or a structured debate – with a group of AI people, 30 minutes per discussion.
Two collaborative sub-skills were assessed: Conflict Resolution (CR) and Project Management (PM). The interviews were rated by two human teaching fellows from New York University and an AI Evaluator (Gemini 3.0), which scored each participant 20 times. A curve is declared NA if any of the 20 predictions are returned by NA; otherwise, the last label was the most common non-NA level among the 20 runs. A regression model – linear for scoring, order of NA decisions – was then trained on these turn-level labels to generate conversation-level scores, with performance assessed using level-one-out validation.
The main results are compelling on several fronts. The level of evidence of the level of change and the level of discussion of behavior related to skills were significantly higher in the Executive LLM conditions than in the independent agent condition in both sub-skills. The interview level knowledge level reached 92.4% for Project Management and 85% for Conflict Resolution when using the Mastery LLM matched skills. Notably, simply telling the participants to focus on the skill did not have a significant effect on the evidence levels (all p>0.6), confirming that the guidance must come from the side of the AI.
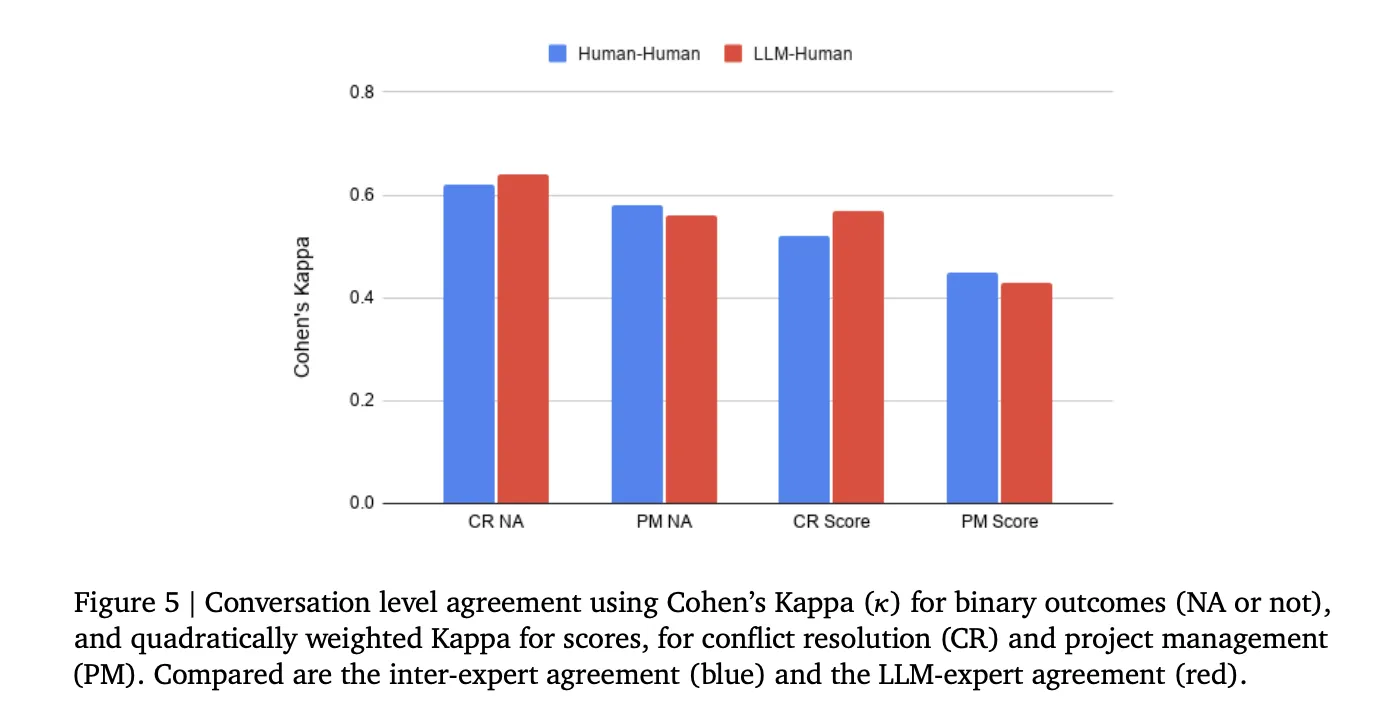
In scoring accuracy, the inter-rater agreement between the AI Tester and human experts – measured by Cohen’s Kappa – was comparable to the interrater agreement, which ranged from moderate (κ = 0.45–0.64) for both skills and both scoring tasks.
Acting as a development sandbox
Another useful finding for ML developers building similar systems is the validation of LLM-based simulations such as the orientation of human subjects during protocol development. The research team used Gemini to simulate human participants at known ability levels (1–4 on each rubric side), then measured retrieval error — the absolute average difference between the ground truth level and the author’s target level. Executive LLM produced significantly lower recovery error than Independent Agents for both CR and PM. The attribute patterns in the simulated data closely resemble those from real human interviews, suggesting that rubric-based simulations can eliminate the risk of experimental design prior to the collection of costly human data.
Standards of Evidence Extend to All Art and Critical Thinking
Through creativity and critical thinking, preliminary levels of evidence have been evaluated using simulated studies. The results show the Executive LLM performs better than the Independent agents in all 8 dimensions tested – all six creativity dimensions (Fluidity, Autonomy, Quality, Ideation, Clarity, and Choice) and the dimensions of critical thinking (Interpret and Analyze; Evaluate and Judge) – with all statistically significant differences. The research team noted that the collection of human measurements in these two skills is ongoing and the results will be shared in future work, but the simulation results suggest that the Executive LLM method includes more than collaboration.
Creativity Scoring at 0.88 Pearson Correlation
In a separate partnership with OpenMic, an institute that develops robust AI-powered skills assessment tools, the research team tested their Gemini-based composition machine on complex multimedia tasks completed by 280 high school students. Activities include designing a story piece based on a short story, including generating interview questions for the characters. Importantly, 100 presentations were used first to refine the Gemini information and expert teaching rubrics, while the remaining 180 presentations were used for final accuracy testing. Rubric-based scores by OpenMic experts and the vendor agreed at Cohen’s Kappa = 0.66 (good agreement) at the item level. Even more surprising, when all submitted scores were compared, the Pearson’s correlation between the author’s total and the person’s expertise was 0.88 — a level of agreement that is difficult to achieve even among human raters of specific creative tasks.
Closing the feedback loop
Beyond scoring, Vantage presents results to users through a multi-skill map that shows competency levels across all skills and sub-skills, with the option to drill down to specific conversation quotes that confirm numerical scores. This makes test evidence visible and actionable – a sensible design consideration for anyone building parallel test pipelines where automated score interpretation is important.
Key Takeaways
- One ‘Executive LLM’ passes many independent agents in the skills assessment: Rather than using a single LLM per AI team partner, Google’s Vantage uses a single LLM connection that generates responses for all AI participants. This allows him to actively guide discussions using a teaching rubric – to introduce conflict, push back on ideas, or create organizational barriers – to elicit visual evidence of certain skills that may not come naturally.
- The LLM-based scores are now equivalent to human expert ratings: The agreement of the AI Tester with the human raters was compared to the agreement between the two human experts themselves, which only reached a moderate Cohen’s Kappa (0.45–0.64) even after several rounds of rating. This positions automated LLM scoring as a scalable alternative to expensive human annotation of complex, open-ended dialog tasks.
- Telling users to focus on skill doesn’t do anything – the steering wheel has to shift from the AI’s side: Participants who were specifically instructed to pay attention to conflict resolution or project management did not show a statistically significant improvement in evidence (all p > 0.6) compared to those who were not given instructions. Only the Executive LLM’s active supervision produced quantitatively rich test data.
- An LLM simulation can serve as a low-cost sandbox before conducting courses with real people: By simulating participants at known skill levels and measuring how accurately the system reproduced those levels, the research team validated the test protocol without burning through expensive human subjects’ budgets. The simulated and actual interview patterns were qualitatively similar, making this a practical way to replicate the rubrics and prompts early in development.
- AI intelligence scores achieved a 0.88 Pearson correlation with human experts on real student work: In a real-world test submitted to 180 high school students, the Gemini-based recorder matched human expert scores at a Pearson correlation of 0.88 on a comprehensive creativity test – showing that automatic scoring of complex, imaginative, multimedia tasks is not only theoretically possible but historically validated.
Check out Paper again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us

Michal Sutter is a data science expert with a Master of Science in Data Science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at turning complex data sets into actionable insights.



