

Retrieval is where most RAG systems quietly break down. Native pipelines rely on vector matching—embedding queries and document fragments in the same location and retrieving the same “closest” match. But uniformity is a poor proxy for what we really need: compatibility based on logic. In longer, professional documents—such as financial reports, research papers, or legal documents—the correct answer is often not in the same paragraph. It requires a structure to navigate, understand context, and perform multi-step reasoning at every stage. This is exactly where vector-based RAG starts to break down.
PageIndex designed to solve this gap by rethinking the return to the original principles. Instead of combining documents and searching by embedding, it creates a hierarchy index of the table-of-contents tree and uses LLMs to consult that structure—as if a human expert were to scan paragraphs, drill down, and connect ideas. This makes a vectorless, logic-driven retrieval process that is more interpretable, traceable, and consistent with how information is extracted from complex documents. By replacing parallel searches with systematic searches and tree-based reasoning, PageIndex delivers extremely high retrieval accuracy—demonstrated by its strong performance in benchmarks such as FinanceBench—making it especially effective for domains that demand precision and deep insight.
In this article, we will use PageIndex to index the Seminal Transformer paper – “Attention Is All You Need” — and answer two contradictory questions against it without a single vector or embedding. Instead of encoding a PDF and returning the same, PageIndex builds a hierarchical tree of text categories, then uses GPT-5.4 consulting node summaries and identifying which paragraphs contain the answer — before reading a single word of the full text.
Setting dependencies
For this tutorial, you will need PageIndex keys and the OpenAI API. You can find the same in the same order.
pip install pageindex openai requestsfrom pageindex import PageIndexClient
import pageindex.utils as utils
import os
from getpass import getpass
PAGEINDEX_API_KEY = getpass('Enter PageIndex API Key: ')
pi_client = PageIndexClient(api_key=PAGEINDEX_API_KEY)We import the OpenAI client and configure it with an API key to allow access to LLMs. Then, we define an asynchronous helper function that sends information to the model and returns the generated response.
import openai
OPENAI_API_KEY = getpass('Enter OpenAI API Key: ')
async def call_llm(prompt, model="gpt-5.4", temperature=0):
client = openai.AsyncOpenAI(api_key=OPENAI_API_KEY)
response = await client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
return response.choices[0].message.content.strip()Building a PageIndex Tree
In this piece, we download a Transformer paper directly from arXiv and send it to PageIndex, which processes the PDF and creates a hierarchical tree of its sections – each node stores the title, abstract, and full text of the section. When the tree is ready, we print it to check the structure defined by PageIndex: each chapter, subsection, and nested title becomes a place in the tree, preserving the natural organization of the document just as the authors intended.
# ─────────────────────────────────────────────
# Step 1: Build the PageIndex Tree
# ─────────────────────────────────────────────
# 1.1 Download the Transformer paper and submit it
import os, requests
pdf_url = "
pdf_path = os.path.join("data", pdf_url.split("/")[-1])
os.makedirs("data", exist_ok=True)
print("Downloading 'Attention Is All You Need'...")
response = requests.get(pdf_url)
with open(pdf_path, "wb") as f:
f.write(response.content)
print(f" Saved to {pdf_path}")
doc_id = pi_client.submit_document(pdf_path)["doc_id"]
print(f" Idokhumenti ithunyelwe. doc_id: {doc_id}") # 1.2 Buyisa isihlahla (i-poll ize isilungile) ukuphrinta kwesikhathi sokungenisa("nIlinde isihlahla se-PageIndex ukuthi silunge"isiphetho="") kuyilapho kungenjalo pi_client.is_retrieval_ready(doc_id): phrinta("."isiphetho=""flush=Iqiniso) isikhathi. sleep(5) tree = pi_client.get_tree(doc_id, node_summary=Iqiniso)["result"]
phrinta ("nn Text Tree Structure:") utils.print_tree(tree)
Saved to {pdf_path}")
doc_id = pi_client.submit_document(pdf_path)["doc_id"]
print(f" Idokhumenti ithunyelwe. doc_id: {doc_id}") # 1.2 Buyisa isihlahla (i-poll ize isilungile) ukuphrinta kwesikhathi sokungenisa("nIlinde isihlahla se-PageIndex ukuthi silunge"isiphetho="") kuyilapho kungenjalo pi_client.is_retrieval_ready(doc_id): phrinta("."isiphetho=""flush=Iqiniso) isikhathi. sleep(5) tree = pi_client.get_tree(doc_id, node_summary=Iqiniso)["result"]
phrinta ("nn Text Tree Structure:") utils.print_tree(tree) Saved to {pdf_path}")
doc_id = pi_client.submit_document(pdf_path)["doc_id"]
print(f"
Saved to {pdf_path}")
doc_id = pi_client.submit_document(pdf_path)["doc_id"]
print(f" Idokhumenti ithunyelwe. doc_id: {doc_id}") # 1.2 Buyisa isihlahla (i-poll ize isilungile) ukuphrinta kwesikhathi sokungenisa("nIlinde isihlahla se-PageIndex ukuthi silunge"isiphetho="") kuyilapho kungenjalo pi_client.is_retrieval_ready(doc_id): phrinta("."isiphetho=""flush=Iqiniso) isikhathi. sleep(5) tree = pi_client.get_tree(doc_id, node_summary=Iqiniso)["result"]
phrinta ("nn
Idokhumenti ithunyelwe. doc_id: {doc_id}") # 1.2 Buyisa isihlahla (i-poll ize isilungile) ukuphrinta kwesikhathi sokungenisa("nIlinde isihlahla se-PageIndex ukuthi silunge"isiphetho="") kuyilapho kungenjalo pi_client.is_retrieval_ready(doc_id): phrinta("."isiphetho=""flush=Iqiniso) isikhathi. sleep(5) tree = pi_client.get_tree(doc_id, node_summary=Iqiniso)["result"]
phrinta ("nn Text Tree Structure:") utils.print_tree(tree)
Text Tree Structure:") utils.print_tree(tree)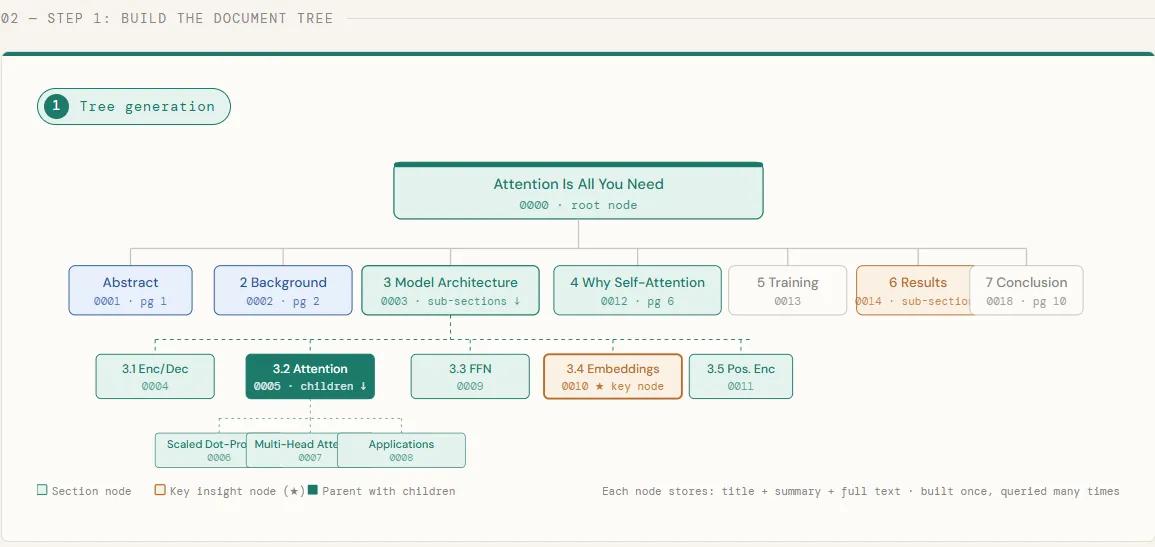
Inference-Based Retrieval
With the construction of the tree, we are now running a deliberately divisive question – one that cannot be answered in one part of the paper. We strip the full text from each node, leaving only the titles and summaries, and transfer the entire tree structure to GPT-5.4. The model then reasons through these summaries to identify every node that is likely to contain the correct answer, returning both its step-by-step reasoning and a list of matched node IDs. This is the core of what makes PageIndex different: LLM decides where to look before any full text is loaded.
# ───────────────────── ────────────────────── # Isinyathelo sesi-2: Ukubuyisa Okusekelwe Ekucabangeni # ───────────────────── ────────────────────── # 2.1 Chaza umbuzo odinga ukuzulazula kuzo zonke izigaba ngenisa json # Lo mbuzo unqanyulwa ngamabomu -- awukwazi ukuphendulwa # ngesigaba esisodwa, okulapho ukusesha kwesihlahla kukhanya khona ngaphezulu kwe-top-k. umbuzo = "Kungani ababhali bakhethe ukuzinaka kunokuphinda, futhi yiziphi izinto eziyinkimbinkimbi zokuhwebelana abaziqhathanisayo?"
tree_without_text = utils.remove_fields(tree.copy(), fields=["text"]) search_prompt = f"""
Unikezwa umbuzo kanye nesakhiwo sesihlahla esilandelanayo sephepha locwaningo. Inodi ngayinye ine-node_id, isihloko, nesifinyezo sokuqukethwe kwayo. Umsebenzi wakho: thola WONKE amanodi okungenzeka aqukethe ulwazi olubalulekile ekuphenduleni umbuzo. Cabanga ngokucophelela -- impendulo ingase isabalale ezigabeni eziningi. Umbuzo: {query} Isihlahla sombhalo: {json.dumps(tree_without_text, indent=2)} Phendula KUPHELA ngale fomethi ye-JSON, asikho isendlalelo: {{
"ukucabanga": "",
"node_list": ["node_id_1", "node_id_2", ...]
}}
"""
phrinta (f' Query: "{query}"n')
print("Running tree search with GPT-5.4...")
tree_search_result = await call_llm(search_prompt)
# 2.2 Inspect the retrieval reasoning and matched nodes
node_map = utils.create_node_mapping(tree)
result_json = json.loads(tree_search_result)
print("n LLM Isizathu:") utils.print_wrapped(umphumela_json["thinking"]) phrinta ("n Nodes found:") for node_id in result_json["node_list"]: area = map_map[node_id]
print (f" • [{node['node_id']}]Page { node['page_index']:>2} -- {location['title']}")  Query: "{query}"n')
print("Running tree search with GPT-5.4...")
tree_search_result = await call_llm(search_prompt)
# 2.2 Inspect the retrieval reasoning and matched nodes
node_map = utils.create_node_mapping(tree)
result_json = json.loads(tree_search_result)
print("n
Query: "{query}"n')
print("Running tree search with GPT-5.4...")
tree_search_result = await call_llm(search_prompt)
# 2.2 Inspect the retrieval reasoning and matched nodes
node_map = utils.create_node_mapping(tree)
result_json = json.loads(tree_search_result)
print("n LLM Isizathu:") utils.print_wrapped(umphumela_json["thinking"]) phrinta ("n
LLM Isizathu:") utils.print_wrapped(umphumela_json["thinking"]) phrinta ("n Nodes found:") for node_id in result_json["node_list"]: area = map_map[node_id]
print (f" • [{node['node_id']}]Page { node['page_index']:>2} -- {location['title']}")
Nodes found:") for node_id in result_json["node_list"]: area = map_map[node_id]
print (f" • [{node['node_id']}]Page { node['page_index']:>2} -- {location['title']}")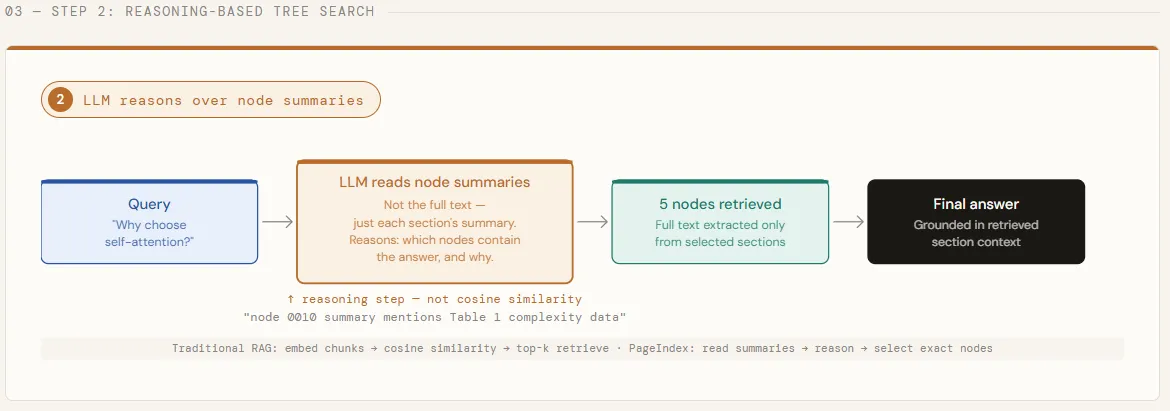
Answer Generation
Once relevant nodes are identified, we pull their full text and combine them together into a single context block – each section is clearly labeled so the model knows where each piece of information comes from. That compiled context is then provided to GPT-5.4 in a structured command that asks for the prime mover, some complex numbers, and any caveats agreed upon by the authors. The model responds using only what is returned, backing up all claims directly from the paper’s text.
# ─────────────────────────────────────────────
# Step 3: Answer Generation
# ─────────────────────────────────────────────
# 3.1 Stitch together context from all retrieved nodes
node_list = result_json["node_list"]
relevant_content = "nn---nn".join(
f"[Section: {node_map[nid]['title']}]n{node_map[nid]['text']}"
for nid in node_list
)
print(f"n Retrieved Context Preview (first 1200 chars):n")
utils.print_wrapped(relevant_content[:1200] + "...n")
# 3.2 Generate a structured answer grounded in the retrieved sections
answer_prompt = f"""
You are a technical assistant. Answer the question below using ONLY the provided context.
Be specific -- reference actual design choices, numbers, and trade-offs mentioned in the text.
Question: {query}
Context:
{relevant_content}
Structure your answer as:
1. The core motivation for choosing self-attention
2. The specific complexity comparisons made (include any tables or numbers)
3. Any caveats or limitations the authors acknowledged
"""
print(" Ikhiqiza impendulo...n") impendulo = linda call_llm(answer_prompt) phrinta ("─" * 60) ukuphrinta (" final response:n") utils.print_folded(response) print("─" * 60) Retrieved Context Preview (first 1200 chars):n")
utils.print_wrapped(relevant_content[:1200] + "...n")
# 3.2 Generate a structured answer grounded in the retrieved sections
answer_prompt = f"""
You are a technical assistant. Answer the question below using ONLY the provided context.
Be specific -- reference actual design choices, numbers, and trade-offs mentioned in the text.
Question: {query}
Context:
{relevant_content}
Structure your answer as:
1. The core motivation for choosing self-attention
2. The specific complexity comparisons made (include any tables or numbers)
3. Any caveats or limitations the authors acknowledged
"""
print("
Retrieved Context Preview (first 1200 chars):n")
utils.print_wrapped(relevant_content[:1200] + "...n")
# 3.2 Generate a structured answer grounded in the retrieved sections
answer_prompt = f"""
You are a technical assistant. Answer the question below using ONLY the provided context.
Be specific -- reference actual design choices, numbers, and trade-offs mentioned in the text.
Question: {query}
Context:
{relevant_content}
Structure your answer as:
1. The core motivation for choosing self-attention
2. The specific complexity comparisons made (include any tables or numbers)
3. Any caveats or limitations the authors acknowledged
"""
print(" Ikhiqiza impendulo...n") impendulo = linda call_llm(answer_prompt) phrinta ("─" * 60) ukuphrinta ("
Ikhiqiza impendulo...n") impendulo = linda call_llm(answer_prompt) phrinta ("─" * 60) ukuphrinta ("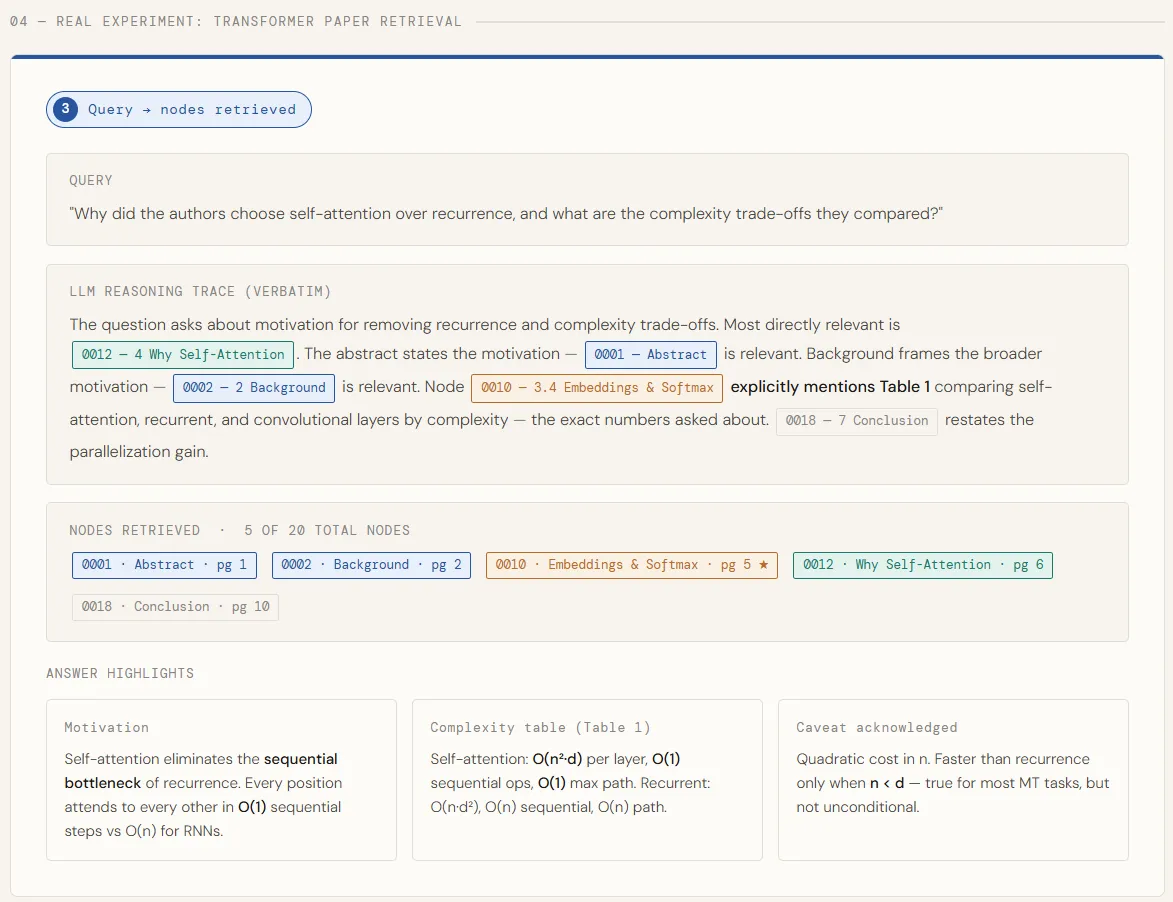

Check with the second question
To demonstrate that the tree can be built once and reused without additional cost, we run a second query – this time targeting a localized approach instead of a discrete design decision. The same tree structure is carried over to GPT-5.4, which narrows its search to just the attention clauses, finds its full text, and produces a clean explanation of how multi-head attention works and why the scaling factor is important. No redirection, no re-embedding — just a new query against the same tree.
query2 = "How does the multi-head attention mechanism work, and what is the role of scaling in dot-product attention?"
search_prompt2 = f"""
You are given a question and a hierarchical tree structure of a research paper.
Identify all nodes likely to contain the answer.
Question: {query2}
Document tree:
{json.dumps(tree_without_text, indent=2)}
Reply ONLY in this JSON format:
{{
"thinking": "<reasoning>",
"node_list": ["node_id_1", ...]
}}
"""
print(f'nn Second Query: "{query2}"n')
result2_raw = await call_llm(search_prompt2)
result2 = json.loads(result2_raw)
print(" Ukubonisana:") utils.print_wrapped(umphumela2["thinking"]) ezifanele_okuqukethwe2 = "nn---nn".joyina(f"[Section: {node_map[nid]['title']}]n{nodi_map[nid]['text']}"
ngoba nid kumphumela2["node_list"]
) impendulo_prompt2 = f"""
Phendula umbuzo olandelayo usebenzisa KUPHELA umongo onikeziwe. Chaza indlela ngokucacile, njengokungathi iposi lebhulogi lobuchwepheshe. Umbuzo: {query2} Umongo: {relevant_content2}
"""
answer2 = wait call_llm(answer_prompt2) phrinta("n Response:n") resources.print_folded(response2)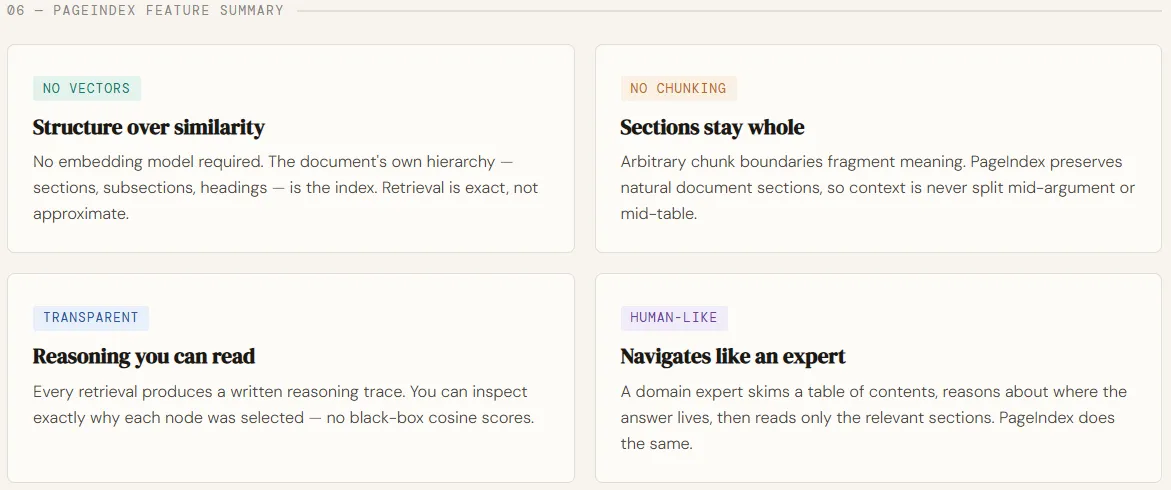
Check it out Full Codes here. Get 100s of ML/Data Science Colab Notebooks here. Also, feel free to follow us Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.?Connect with us
The post RAG Without Vectors: How PageIndex Returns Through Consultation appeared first on MarkTechPost.



